
You’re probably living some version of this right now.
A new product is supposed to go live by Friday. The supplier sent specs in one spreadsheet. Marketing has lifestyle images in a shared drive. Sales wants one title for Amazon, another for Walmart Marketplace, and shorter bullets for Google Shopping. Customer service flagged that the dimensions on last month’s launch were wrong. Meanwhile, the inventory feed says one thing, the ERP says another, and someone is asking why the BOPIS listing still shows stock in a store that has none.
That doesn’t feel like a strategy problem. It feels like a Tuesday.
In the retail and cpg industry, that kind of mess is no longer a side effect of growth. It’s the thing that decides whether teams can grow at all. The brands and retailers that win now aren’t always the biggest. They’re the ones that can get product data clean, complete, approved, and published without turning every launch into a fire drill.
A lot of teams still act like product content is an admin task. It isn’t. It sits right in the middle of pricing, shelf visibility, conversion, fulfillment, returns, and retail relationships.
That matters more now because the easy growth period is gone.
In 2024, global retail sales for consumer products reached $7.5 trillion, but growth slowed, and about 75% of that sales expansion came from price hikes rather than volume increases according to Bain’s consumer products report. When growth leans that heavily on price, every weak process gets exposed fast.

When prices stop carrying the business, operators have to. Teams can’t rely on inflation to hide bad catalog structure, missing attributes, or slow content updates.
A few things show up at the same time:
The result is familiar. One team edits the title. Another updates the size. A third swaps packaging imagery. Nobody is fully sure what the “current” product record is.
Spreadsheets work for small catalogs and forgiving channels. They break when the business starts selling the same item in multiple formats, regions, languages, and retailer templates.
I’ve seen this pattern over and over. The problem isn’t that teams are careless. It’s that they’re trying to run a modern product operation with tools built for one owner and one version.
Practical rule: If three departments are editing the same SKU in separate files, you do not have a catalog process. You have a collision schedule.
That’s why the conversation in the retail and cpg industry has shifted. The problem isn’t just “how do we add AI.” The problem is “how do we stop product data from breaking every downstream process that depends on it.”
Product data doesn’t get messy all at once. It drifts. A field gets renamed. A supplier sends values in a different format. A retailer needs a new attribute. Marketing crops a new hero image and saves it with a filename nobody can find later.
That slow drift is what I call data entropy. Left alone, every catalog becomes less reliable over time.
Take a simple packaged item. The manufacturer has a master spec sheet. The retailer wants a different category structure. Amazon needs one title format. Google Shopping needs another. Your DTC site wants richer storytelling. A marketplace may require different image ratios, different bullet lengths, and tighter variant grouping.
Now add revisions. The pack count changes. The claim on the front label changes. Legal updates an ingredient disclosure. Suddenly the same product exists in multiple “current” versions across email threads, folders, spreadsheets, and channel exports.
Traditional tools don’t fail because they’re bad. They fail because they have no control layer.
This is why articles like Product Information Management System is important for retailers still matter. Retail teams hit the same wall again and again. At some point, product information needs an actual system of record, not a collection of workarounds.
The quality problem isn’t minor. Syndicated data providers often deliver only 40-60% accuracy, and poor data harmonization is a key reason 50% of BOPIS orders fail due to inventory inaccuracies according to Retail Velocity.
That’s not just a data team issue. That lands on store ops, customer support, and the shopper standing at the pickup desk.
Consider this:
| What breaks | What the shopper sees |
|---|---|
| Wrong inventory sync | “Ready for pickup” turns into “sorry, unavailable” |
| Missing attributes | Confusing comparison between similar items |
| Outdated packaging images | “This isn’t what I thought I ordered” |
| Unclear variant logic | Wrong size, flavor, or pack selected |
If you want a good overview of how product data should move from intake to update to retirement, this breakdown of the information management life cycle is a useful reference.
Many teams underestimate the media side of the problem.
Every SKU can have a stack of assets. Hero image. Side angle. Pack shot. Ingredients panel. Nutritional panel. Lifestyle image. Short demo video. Retailer-specific crop. Marketplace-safe version without extra text. Seasonal creative. Updated packaging shot.
Now multiply that by variants and channels.
What works is boring, but effective. Standard naming. fixed metadata rules. one taxonomy. one owner for final approval. What doesn’t work is letting every team invent its own structure and hoping search can save you later.
The catalog usually doesn’t collapse because of one major failure. It collapses because nobody designed how updates should flow.
The cleanest way to explain an AI-powered PIM and DAM is this. Consider it a central kitchen.
Raw ingredients come in from everywhere. Supplier files, ERP exports, channel requirements, packaging copy, images, videos, compliance notes. If you leave them in separate bags on separate counters, dinner service falls apart. If you prep them in one kitchen with one workflow, you can plate the same ingredients differently for different diners.
That’s what a modern product content setup does.
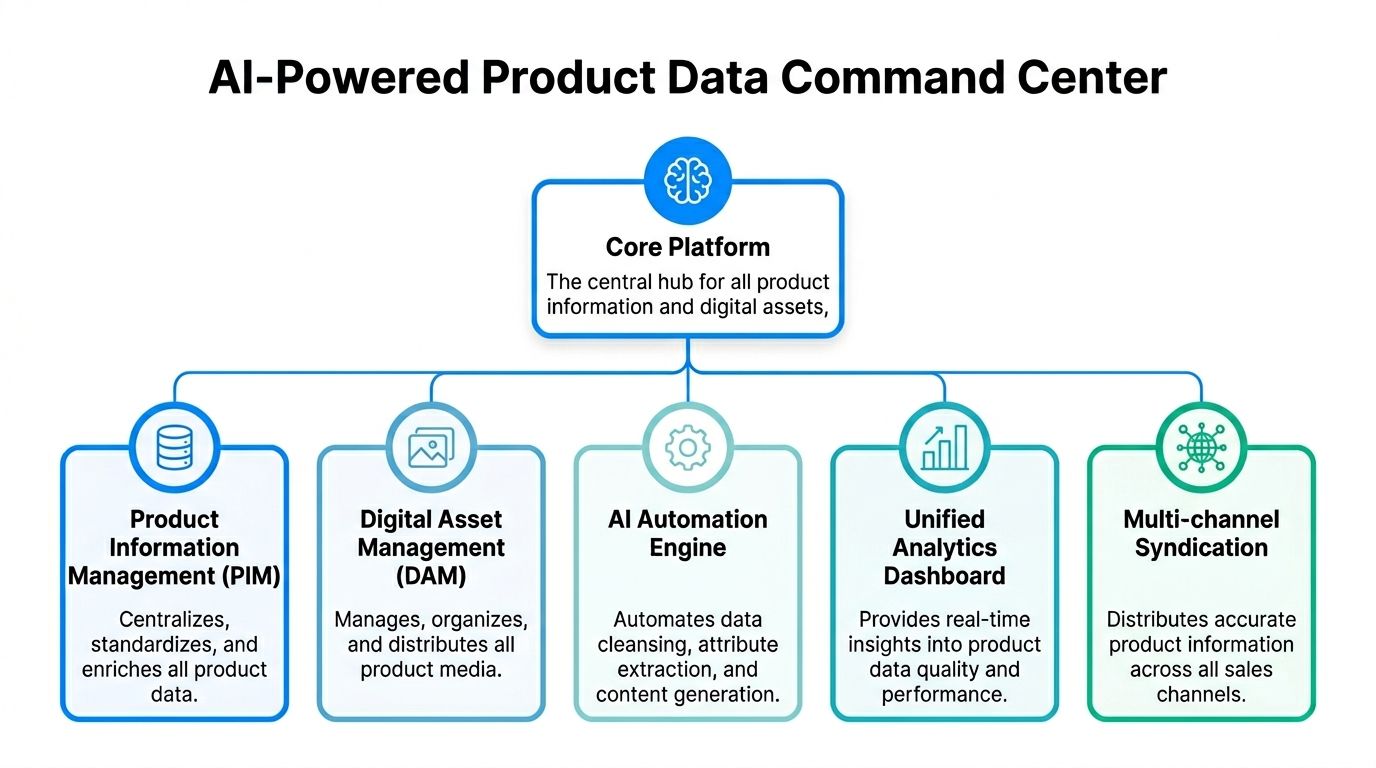
A good setup has one central source of truth for product data and one controlled library for digital assets.
The pieces are straightforward:
Without AI, that system already improves control. With AI, it starts doing the repetitive prep work that normally burns team time.
AI is useful when the job is repetitive, rules-driven, and still needs review.
In practice, that means it can help with:
| Task | Where AI helps |
|---|---|
| Attribute cleanup | Standardizes messy supplier values |
| Content enrichment | Expands bare specs into usable copy |
| Asset tagging | Identifies product type, pack, angle, usage scene |
| Channel formatting | Adapts titles, bullets, and descriptions by destination |
| Quality checks | Flags missing fields, mismatched variants, weak completeness |
That doesn’t mean AI should publish unchecked content. It means AI should handle the first draft and the first pass of structure, so people can focus on judgment.
A strong overview of that media side is this guide to digital asset management with AI.
Many teams think they need “better content creation.” What they need is a better content system.
Once data and assets live in a command center, a few things change fast:
Working rule: AI should prepare product content at scale. Humans should decide what is brand-safe, channel-safe, and commercially smart.
That’s the difference between using AI as a gimmick and using it as infrastructure.
The best proof isn’t a feature list. It’s what a team can finish before lunch that used to take three days.
In the retail and cpg industry, the pressure is getting sharper. Retail media spending is projected to reach $62 billion by 2025, private label sales have surged, and brands using CPG data analytics are achieving 69% higher revenue growth by reacting faster to trends and optimizing content for targeted channels according to ParallelDots. When shelf competition gets tighter, slow content operations become expensive.
A common starting point is ugly source material. Maybe it’s an ERP export with short field names, incomplete dimensions, and a technical description no shopper would ever read.
The team loads it into the product hub. AI maps attributes, normalizes units, and builds a usable draft. Then the eCommerce manager reviews the result and adjusts for tone, claims, and channel rules.
What works:
What doesn’t work:
A lot of teams talk about SEO, but product discovery is shifting toward answer engines, shopping assistants, and retailer-native recommendation layers. For that world, Generative Engine Optimization, or GEO, depends on clean attributes and complete context.
The headline matters, but structured facts matter more.
If you sell household, beauty, or food products, the winning record usually includes:
That’s how teams feed Google Shopping, marketplaces, brand sites, and retail media campaigns without rebuilding the listing every time.
Private label pressure changes the pace of execution. If a retailer rolls out a competing option, the response can’t take weeks.
A strong AI-PIM workflow helps teams launch a refreshed variant, pack update, or channel-specific bundle faster because they reuse structured product families instead of starting over. The parent record holds the shared truth. Child variants inherit what should stay the same. Teams only edit what’s different.
That’s especially useful when packaging changes but base specs don’t.
The fastest teams don’t create more content manually. They reuse approved structure and only change what the channel or shopper needs.
A short walkthrough helps here:
Later in the workflow, rich media matters just as much as clean text. This video shows the kind of product content process modern teams are trying to streamline.
One of the hardest jobs is keeping the same product recognizable across a dozen retailer sites without making every listing identical.
That’s where AI helps if the rules are good.
A team can define a base brand voice and then layer channel rules on top. Amazon might need stronger feature bullets. A retailer PDP may need tighter compliance language. Google may need more attribute precision. The copy changes, but the product truth does not.
That’s the sweet spot. One master record. Many customized outputs.
Operations teams usually ask the right question. Not “is the platform smart?” but “what moves after we implement it?”
The return shows up in execution first, then in financial performance.
You don’t need a giant scorecard at the start. You need a handful of measures that tell you whether the catalog is becoming more usable.
The most practical ones are:
The planning side matters a lot. CPG brands that use integrated data for analytics achieve 85%+ accuracy in demand forecasting, leading to 69% higher revenue uplift and 72% cost savings compared to peers who rely on intuition, which also helps reduce the bullwhip effect according to SR Analytics.
That kind of improvement doesn’t come from copy alone. It comes from getting the underlying product data and channel data into one usable model.
Some gains are obvious. Some are operational, but still valuable.
| ROI type | What improves |
|---|---|
| Hard ROI | Better demand planning, fewer channel errors, lower rework |
| Commercial ROI | Stronger PDP quality, faster launch readiness, better retail media support |
| Team ROI | Less copy-paste work, clearer ownership, fewer cross-team disputes |
| Brand ROI | More consistent listings, fewer outdated assets, tighter control of approved claims |
The trap is expecting one number to tell the whole story. In practice, ROI shows up as fewer delays, fewer reversals, and fewer “which file is final” conversations.
The first win is rarely magical AI writing. It’s usually control.
A few signs that the system is paying off:
Operational test: If a retailer asks for an attribute update today, your team should know exactly where to change it, who approves it, and which channels inherit it.
That’s the point where a catalog stops being a burden and starts acting like infrastructure.
Many teams get stuck because they treat implementation like a giant switch. It works better as a staged rollout. Crawl. Walk. Run.
That approach lowers risk and gives the team visible wins early.
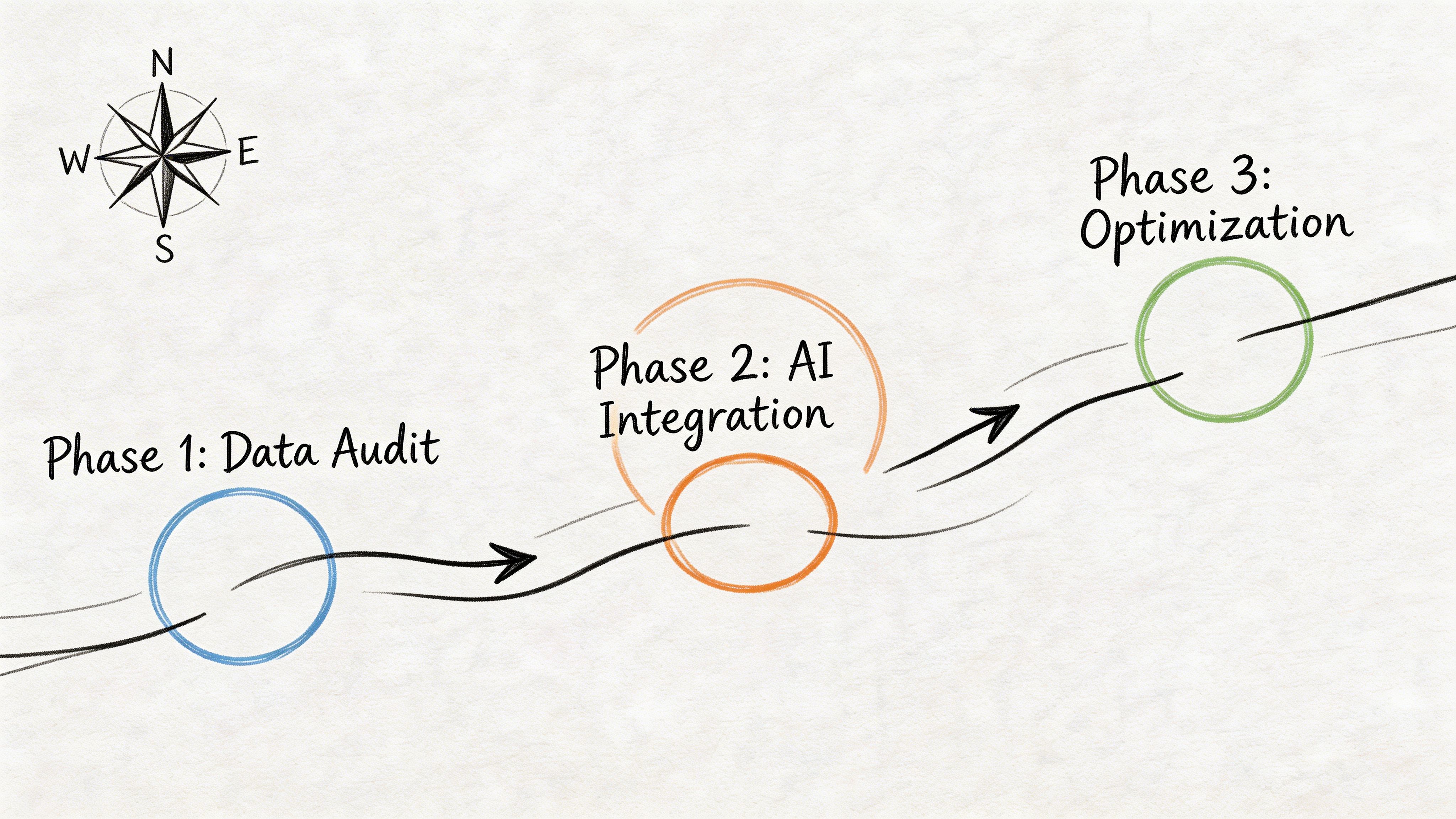
Start by centralizing what already exists. Not perfectly. Bring together:
Don’t begin with AI writing. Begin with data intake, duplicate detection, and asset matching. If the foundation is weak, automation just spreads the mess faster.
Here, a solid data integration platform mindset matters. Teams need a place to import, compare, and reconcile updates before they hit live channels.
A useful side lesson comes from warehouse design too. This piece on WMS integrated warehouse design where data defines your layout gets at the same operational truth. If the underlying data model is messy, the physical or digital workflow built on top of it stays messy.
Once the core records are centralized, define how the catalog should behave.
Set the operating rules:
| Decision area | What to define |
|---|---|
| Ownership | Who edits, who approves, who publishes |
| Taxonomy | Categories, variants, and attribute naming |
| Asset rules | File naming, metadata, approved usage |
| Exceptions | What requires legal or compliance review |
| Channels | Which outputs go live first |
This stage should stay narrow. Pick one or two high-impact channels. Build the templates. Test field mapping. Learn where the edge cases are.
That gives the team room to fix structure before the rollout gets wide.
Once the data model is stable, AI starts doing real work.
Use it for:
This is also where versioning is essential. AI can create a lot of content very quickly. If you don’t know what changed and who approved it, you’ve built a speed problem, not a control system.
Start narrow, but design for scale. The right workflow for 5,000 SKUs should still make sense when the catalog is much larger.
The teams that succeed usually do three things well:
That’s the practical path. Not a giant transformation deck. A sequence of controlled improvements that make the next one easier.
Once the system is live, the true test begins. Scaling exposes every weak rule you skipped in the setup phase.
My advice is simple. Get stricter as you grow, not looser.
Catalog scale punishes “we’ll fix it later.” If teams can create attributes freely, upload assets with random names, or publish AI-generated copy without review, quality drops fast.
Use a human-in-the-loop workflow by default. That matters even more as GEO becomes part of product discovery. According to HFS Research, a key challenge for scaling CPG firms is the tech-deprived gap in managing unified product data for GEO, and only 59% of executives foresee agentic AI owning consumer relationships, which reinforces the need for reviewable workflows and control of brand voice.
The cleanest teams separate responsibilities clearly.
If nobody owns the rulebook, everyone improvises.
Don’t scale by writing more. Scale by designing records that can be reused safely.
That usually means:
A lot of teams try to solve discovery with better phrasing. Better phrasing helps. But GEO starts with structured truth.
If you want consistent performance across Amazon, Google, marketplaces, and DTC, make sure your catalog can answer basic machine-readable questions cleanly. What is it. What are the variants. What problem does it solve. What claims are approved. Which assets support that answer.
AI should speed up production. Governance should protect trust. You need both.
That balance is what keeps a growing catalog usable instead of chaotic.
The retail and cpg industry has changed. Growth is harder to win. Private label is tougher. Retail media is noisier. Channels want cleaner data, faster updates, and better assets.
That means product data can’t sit in the background anymore.
When teams centralize product information, govern digital assets, and use AI for enrichment instead of guesswork, the whole operation gets sharper. Listings go live with less rework. Teams spend less time fixing avoidable mistakes. Channel content becomes adaptable without becoming inconsistent.
The future isn’t about adding AI to a broken process. It’s about building a process where AI has clean inputs, clear rules, and human review.
That’s how you move from chaos to control.
If your team is ready to centralize product data, clean up digital assets, and create channel-ready content with built-in human review, take a look at NanoPIM. It’s built for brands and retailers that need one source of truth for specs, variants, and media, then want to turn that foundation into GEO-ready content for Amazon, Google, eBay, and beyond.


