
You’re probably dealing with some version of this already.
A supplier sends a spreadsheet with fresh specs. Your marketplace team edits titles for Amazon. Your brand team swaps images in Dropbox. Someone in merchandising updates dimensions in the ERP. Then an AI tool rewrites bullets for Google Shopping. A week later, customer support is fielding returns because the size chart on one channel doesn’t match the product page on another.
That kind of mess usually gets blamed on bad process, slow teams, or the wrong tool. In practice, it’s often a split-brain data problem. One side of the business is trying to move, clean, publish, and sync product information. The other side hasn’t clearly decided who owns the rules, who approves changes, and what “correct” even means.
That’s where data management vs data governance stops being an IT debate and becomes a retail operations issue.
A common retail scenario looks harmless at first.
A brand launches a new product line. The manufacturer sends technical specs through one system. Marketing rewrites descriptions in another. Images live somewhere else. Channel teams adjust titles and attributes to meet Amazon, Google, and eBay requirements. Then a returns spike exposes the problem. The dimensions were updated in one place, but the old values kept flowing to two channels and a printed spec sheet.
Nobody usually says, “We have a governance issue.” They say, “Why is the catalog always wrong?”
You’ll see it in small, expensive ways:
This isn’t just messy data entry. It’s two missing disciplines acting like one.
Product data chaos usually means the business hasn’t separated the rules from the execution.
Data governance decides who owns product fields, what standards apply, which changes need approval, and how compliance gets enforced.
Data management makes the actual work happen. It moves files, maps attributes, validates feeds, stores media, merges updates, and pushes product data to the right channels.
Retail teams need both. If you only focus on moving data faster, you’ll move bad data faster. If you only define rules, you’ll create a policy binder nobody can operationalize.
The easiest way to understand the difference is to think of a city.
The city government decides zoning laws, safety codes, and who can approve what gets built. Construction crews, utility teams, and road workers do the physical work that makes the city run day to day.
That’s the split between governance and management.
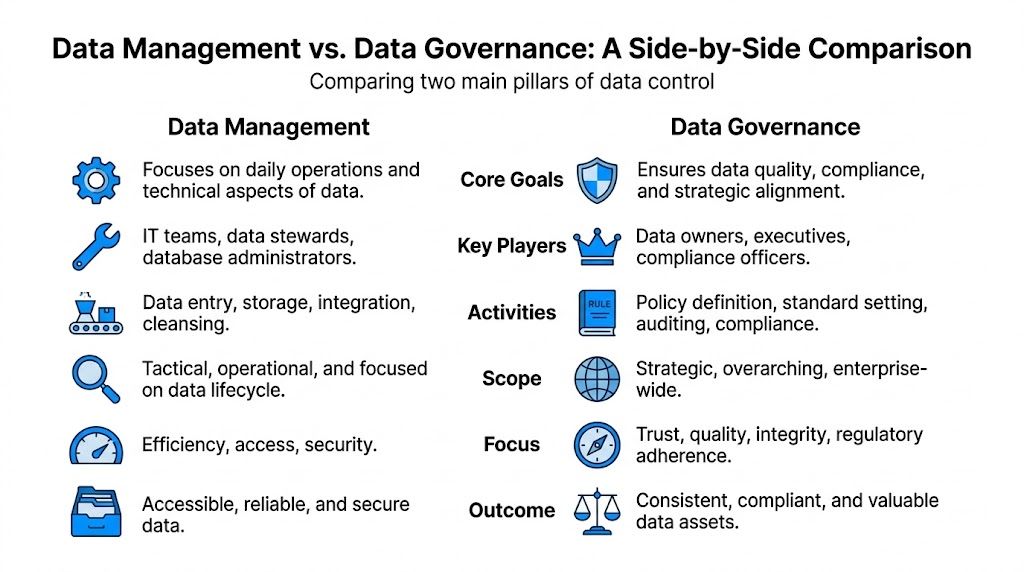
Data governance is the decision system for data. It defines ownership, standards, policy, quality expectations, and accountability.
Data management is the operating system for data. It handles collection, storage, integration, processing, delivery, and technical enforcement.
Governance answers the business questions.
Who owns product title standards. Which attributes are mandatory before a SKU can go live. What counts as a valid size value. Which users can change compliance-sensitive fields. What audit trail needs to exist when a supplier spec gets overwritten.
Many companies encounter difficulties. Only 19% of U.S. enterprises have fully implemented data governance strategies, according to Actian’s explanation of data governance vs data management. That gap often shows up when teams buy strong management tools but never set the strategic rules that keep those tools aligned with the business.
In eCommerce, governance often includes:
If you’re tightening standards, a good data quality framework can help structure how you define completeness, validity, and consistency before you try to automate anything.
Management handles the doing.
It brings supplier data in through APIs, CSV imports, or ERP syncs. It maps source fields to your product model. It runs validation checks. It stores images and docs. It tracks versions. It updates channels. It catches failed syncs before they become listing issues.
The key point is simple. Management doesn’t decide the rules. It enforces them.
A useful perspective on this is:
Retail teams often say “we need better data management” when the problem is ownership. Or they say “we need governance” when the issue is that nobody built workable pipelines.
That’s why a real plan needs both a policy layer and an execution layer. If you’re trying to put the operating side in order, this guide to a data management strategy is the right companion to the governance work.
A side-by-side view helps because these two disciplines overlap around the same data, but they do different jobs.
| Area | Data governance | Data management |
|---|---|---|
| Primary role | Sets rules, standards, ownership, and accountability | Executes data collection, storage, movement, and delivery |
| Main question | Who decides and why | How it gets done |
| Typical owners | Executives, data owners, compliance leaders, stewards | Engineers, admins, PIM operators, integration teams |
| Focus in retail | Metadata standards, approval rules, channel compliance, field ownership | Imports, mappings, enrichment flows, syndication, versioning |
| Main risk if missing | Teams publish data nobody can trust | Teams define rules nobody can operationalize |
Governance cares about whether data is trustworthy, compliant, and aligned with business intent.
Management cares about whether data is available, current, structured correctly, and flowing to the right place at the right time.
In retail, governance asks things like:
Management asks:
This sounds theoretical until a channel rejects hundreds of listings because required attributes were interpreted differently by different teams.
Governance is usually led by business stakeholders with decision authority. That can include a chief data officer, data owner, category lead, compliance lead, or a cross-functional governance council.
Management is usually run by the teams who build and maintain the machinery. That includes PIM admins, data engineers, integration specialists, DBAs, and operations teams.
The problem in retail is that accountability often gets fuzzy fast. A supplier sends poor data. An agency cleans it. An internal team enriches it. A marketplace adds formatting constraints. Then an AI tool rewrites copy. When something goes wrong, every team can point at the previous handoff.
Field rule: If more than one team can change a product attribute, assign one team that owns the final approved definition.
That’s why policy documentation matters. A practical starting point is to define category-level standards and approval rules in one place, similar to these data governance policies.
Governance processes are about decisions and controls.
They include:
Management processes are operational.
They include:
One quick test helps. If the task starts with “define,” it usually leans governance. If it starts with “load,” “map,” “clean,” “merge,” or “publish,” it usually leans management.
The toolsets are different, even when they touch the same product record.
Governance typically uses catalogs, glossaries, lineage tools, policy repositories, and audit workflows. Management relies on databases, ETL pipelines, sync engines, APIs, import tools, and storage systems.
According to Splunk’s breakdown of the difference, governance commonly uses data catalogs and business glossaries and tracks success with metrics such as compliance rates above 95% in mature organizations. Management commonly uses ETL pipelines and databases and tracks operational measures like system uptime above 99.9% and query response times.
That distinction matters in eCommerce software buying. Teams often buy the tool that helps them move data and assume the rules will sort themselves out. They won’t.
Governance success looks like fewer debates about definitions, fewer risky edits, clearer approvals, and more confidence in the catalog.
Management success looks like stable imports, fewer sync failures, cleaner channel feeds, and less manual spreadsheet work.
A retailer with strong management but weak governance often has fast-moving pipelines that spread inconsistent data everywhere.
A retailer with strong governance but weak management often has perfect standards trapped in slide decks and shared docs.
A recipe is useful. A kitchen is useful. Dinner only happens when you have both.
Governance is the recipe. It tells you what the finished result should be, what ingredients are allowed, what quality standard matters, and what can’t be skipped.

Management is the act of cooking. It gets the ingredients into the kitchen, measures them, prepares them, cooks them, and serves the result where people need it.
If governance exists without management, teams know the rules but can’t reliably apply them. You get approved standards with no strong validation, no scalable workflow, and no dependable publishing process.
If management exists without governance, teams can process and push huge volumes of data, but they can’t prove that the data is right, controlled, or safe to use.
That split isn’t just inconvenient. As Apono’s analysis of governance vs management notes, governance without management yields compliant but unusable data, while management without governance leads to functional but overexposed and unauditable data. That matters even more under rules like GDPR, where the policy layer and the execution layer both have to hold up.
Say your business uses AI to rewrite product bullets, generate channel-specific descriptions, and improve merchandising data.
Governance should decide:
Management should handle:
That same logic applies to tools outside commerce operations too. Product teams using AI tools for product feature prioritization face a similar challenge. The model can help process signal, but someone still has to define what counts as an acceptable input, an acceptable recommendation, and an acceptable decision trail.
A short walkthrough helps if your team wants a simple visual explanation before getting into implementation details.
Don’t ask whether a problem is governance or management. Ask whether the issue is missing rules, weak execution, or both.
That framing cuts through a lot of internal confusion. If your product titles are inconsistent, you may need a controlled naming standard. You may also need a workflow that stops unauthorized titles from reaching the feed.
Most catalog problems need both answers.
Teams often don’t need a giant enterprise transformation to get started. They need a workable operating model inside the systems they already use.
The most reliable path is to build governance and management together around the product record. Not around abstract data doctrine. Around the actual fields, assets, approvals, and channel requirements your team deals with every day.
Before assigning owners, define what a clean product record looks like.
For each category, decide the core entities and field groups. Product title. Description. Variant structure. Dimensions. Materials. Media. Compliance fields. Channel-specific attributes. Supplier identifiers. Internal merchandising tags.
Write down three things for each critical field:
This sounds basic. It isn’t. Many retail teams skip this and try to govern a catalog whose structure is already ambiguous.
Most guides get too neat.
In real retail operations, one field can pass through several hands. A manufacturer supplies initial specs. An integration layer maps them. A content team enriches them. A compliance reviewer checks them. A marketplace feed may transform them again.
According to Alation’s discussion of distributed accountability, this is the part many current guides miss. When product data moves from a supplier ERP through an AI enrichment platform to a marketplace, traditional ownership models break. The fix is to define ownership at each stage.
Use a stage-based ownership map like this:
| Stage | Example owner | Accountable for |
|---|---|---|
| Ingestion | Supplier or internal integration team | Source accuracy at handoff |
| Standardization | PIM or data operations team | Mapping, units, normalization |
| Enrichment | Content or AI workflow owner | Value-added copy and metadata |
| Approval | Category manager, compliance, brand | Final sign-off |
| Publication | Channel operations team | Correct feed delivery and channel fit |
The point isn’t to spread blame. It’s to remove ambiguity before something fails.
If a field crosses systems, define who owns it before the handoff, during the handoff, and after the handoff.
Not every field deserves the same level of control.
A missing lifestyle image is inconvenient. A wrong voltage rating, fabric composition, age warning, or ingredient declaration can create far bigger issues. Build your rules based on business risk, not on a generic “all data must be perfect” standard.
A practical model looks like this:
That approach keeps your workflow usable. Teams ignore governance when every single field triggers the same heavy review path.
A common mistake is forcing every product update through the same approval process.
That slows everything down. It also trains teams to work around the system.
A better model is exception-based governance:
That’s where management supports governance well. Your workflow engine, versioning layer, import process, and audit trail should make exceptions easy to catch and easy to resolve.
Agencies, distributors, manufacturers, and content vendors often sit outside the formal org chart but inside the operating chain.
Treat them as governed contributors, not anonymous inputs.
That means:
Retailers that skip this usually end up with a fake “single source of truth.” It’s really just a central place where unmanaged inputs collide.
Annual governance reviews are too slow for commerce teams.
Channel requirements change. Suppliers change formats. New product types get introduced. AI workflows create new content paths. What worked six months ago may now be creating friction.
A short monthly review is usually enough if it focuses on operational signals:
That turns governance into a working discipline instead of a document nobody opens.
In product data work, the best platforms don’t force you to choose between control and speed. They connect them.
That matters because governance and management usually fail at the seam between policy and execution. One system stores the rules. Another handles the imports. A third runs enrichment. A fourth pushes channel feeds. By the time an issue shows up, nobody can reconstruct what changed, who approved it, or whether the update should have happened in the first place.
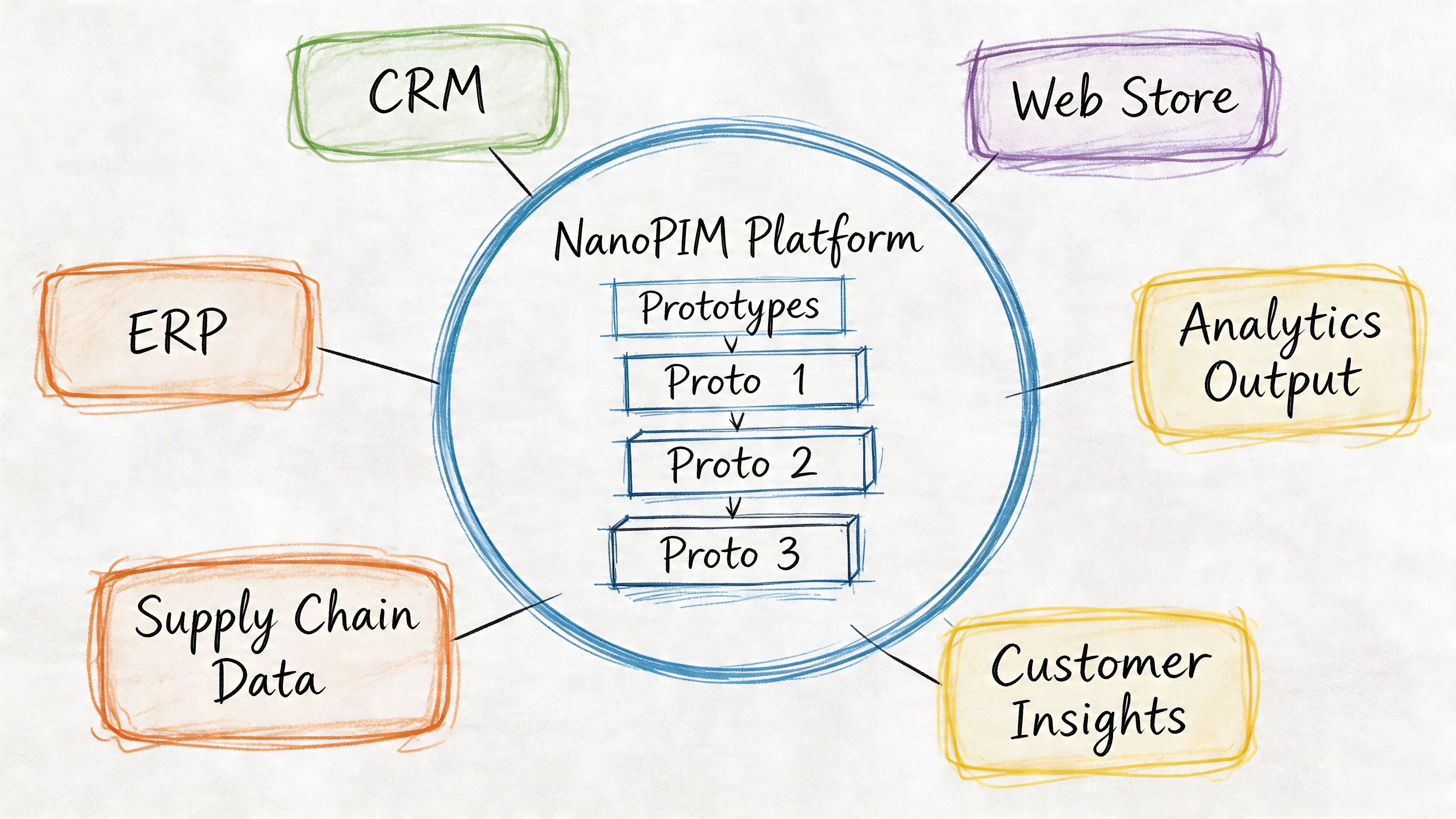
Governance needs structure, consistency, and traceability.
In a PIM and DAM setup, that often means the platform should enforce a stable product model instead of letting every team improvise. NanoPIM’s prototypes and cascading attributes support that by giving teams a repeatable schema for categories, variants, and shared field logic. That’s governance in practice. It turns standards into something operational, not just documented.
The same goes for human-in-the-loop review flows, versioning, and audit trails. Those capabilities support approval logic and accountability. If a supplier update changes a critical attribute, the business can review it before publication. If a team member edits AI-generated copy, there’s a record of what changed and why.
That’s the difference between “we think this data is controlled” and “we can show how this product record evolved.”
Management is the engine room.
NanoPIM handles the movement and execution side through AI-powered enrichment, centralized attributes and media, channel-specific content generation, and integrations with commerce platforms and ERPs. Those are management capabilities because they do the actual work of collecting, transforming, optimizing, and distributing product data.
The Data Holding Bay is a good example. It gives teams a controlled place to import, compare, and merge updates before they hit the live catalog. That’s practical management design. It helps deal with one of the hardest retail problems, which is receiving product updates from multiple external sources without letting those updates overwrite trusted records blindly.
A lot of software handles one side well.
Some tools are strong at workflow and syncs but weak at policy enforcement. Others are good at modeling and approvals but clunky when you need fast enrichment or multi-channel execution.
The useful part of NanoPIM’s design is that it links both sides in one operating flow:
That’s especially relevant for teams working on GEO and marketplace optimization. You want the system to help generate better channel-ready content, but you also need to control what gets published, what gets reviewed, and how source truth is protected.
Good product data platforms don’t replace governance with automation. They make governance executable.
For retailers, agencies, and manufacturers managing complex catalogs, that’s the primary win. The catalog gets faster without becoming less trustworthy.
A data program earns budget when it changes daily operations. In eCommerce, that means fewer supplier fixes at the last minute, faster product launches across channels, and less time spent arguing over which spreadsheet is right.
The KPI split should reflect how the work is distributed. Governance metrics show whether accountability is clear and standards are being followed across teams. Management metrics show whether the catalog operation can process updates, enrich records, and publish reliable data at the speed the business needs.
Governance KPIs answer a simple question. Do people know the rules, and are they following them?
If you need a practical framework for setting targets, this guide to data quality metrics for product teams is a useful reference.
Management KPIs focus on execution. They show whether the machine can keep up when supplier files change, marketplaces add requirements, and AI tools generate more content than a team can review manually.
These metrics matter because speed on its own is expensive. A fast team that republishes bad dimensions, outdated compliance text, or duplicate product content creates returns, listing suppressions, and wasted ad spend.
The strongest signal is operational calm.
Category managers stop chasing missing specs the night before a launch. Marketplace teams spend less time fixing rejected listings. Suppliers get clearer feedback because owners and approval paths are obvious. AI becomes useful because it is working from cleaner structure and better source data, not patching chaos after the fact.
What good looks like is straightforward. The catalog moves faster, channel errors drop, and accountability stops bouncing from team to team.
NanoPIM helps retail teams bring both sides together in one place. You can centralize product data and assets, apply structure through prototypes and metadata models, enrich content with AI, route changes through human review, and keep version history and audit trails intact. If you’re trying to scale a cleaner, faster catalog across channels, explore NanoPIM.


