
So, what is the simple data ingestion meaning? Put simply, it’s the process of getting all your data, from all the different places it lives, into one central spot where you can actually store and use it. Think of it as the foundational first step for any serious data strategy.
Let's cut through the jargon with a simple analogy. Picture a professional kitchen. The head chef needs ingredients from everywhere: fresh vegetables from a local farm, meat from the butcher, and rare spices from a specialty importer. Data ingestion is that kitchen's receiving dock. It's the place where all these raw ingredients are gathered before any cooking can start.
In the world of eCommerce, your data is your ingredients, and it comes from all over the place.
Data ingestion is the critical process that gathers all this raw information and funnels it into a central system, like a Product Information Management (PIM) platform. Without this step, all your powerful analytics tools and AI content generators are completely useless. They’re like a high-tech oven with no food to cook.
The core idea is simple: data ingestion gets your raw data in the door so you can start turning it into something valuable, like accurate product listings or insightful sales reports.
The growing importance of getting this right is clear from the market numbers. The global data integration market, which is full of ingestion tools, was valued at US$11.6 billion in 2022 and is expected to soar to US$26.3 billion by 2031. You can dig deeper into this trend in the full data integration market report. This isn’t just a buzzword. It’s a fundamental business process that’s becoming essential to compete.
To make this crystal clear, let's quickly break down the key parts in a table.
This table simplifies the core components of data ingestion, showing how each piece works in a real-world eCommerce context.
| Component | Simple Explanation | eCommerce Example |
|---|---|---|
| Data Source | Where the information comes from. | A supplier's CSV file or your Shopify store. |
| Data Destination | Where the information is going. | A PIM system or a data warehouse. |
| Data Pipeline | The pathway the data travels. | An automated workflow that moves the data. |
Seeing it laid out this way helps connect the concept to the actual moving parts you’ll be working with. Each component plays a vital role in getting information from point A to point B reliably.
When you're building a a data strategy, one of the first big questions you'll face is this: Should your data arrive in scheduled, predictable bundles, or as a constant, live flow?
This is the core difference between batch ingestion and streaming ingestion. Neither is inherently better. They’re just different tools for different jobs. Getting this choice right is fundamental to building a system that actually works for your business.
Think of batch ingestion like old-school mail delivery. The mail carrier collects all the letters and packages for the day, sorts them, and delivers everything to your mailbox in one big drop. You get a large amount of information at a predictable time, whether that's once a day, once a week, or once a month.
This method is the go-to for large, less urgent tasks. For instance, a supplier might email you their entire updated product catalog every Friday. Since you don't need that data second-by-second, processing it in one large, efficient chunk makes perfect sense. Understanding what is batching in detail is key to knowing when to use this cost-effective approach.
Batch processing is the backbone of countless business operations because it's reliable and efficient for handling huge volumes of data without needing constant supervision.
It’s perfect for things like:
Essentially, batch ingestion trades immediate speed for throughput and efficiency. It’s your best bet when you have a lot of data to move and time isn't the most critical factor.
In contrast, streaming ingestion is like getting live news alerts pushed to your phone. Information arrives the moment it’s created, giving you a real-time view of what's happening right now.
This approach is absolutely critical for time-sensitive operations where even a few minutes of delay can create real problems.
Picture a flash sale on your ecommerce site. When a customer buys the very last unit of a popular item, you need to update your inventory to "Out of Stock" immediately. Not just on your website, but on your Amazon and eBay channels, too. Streaming makes that possible, preventing you from overselling and disappointing customers.
This shift toward immediate data is reshaping the entire retail landscape. The market for real-time data integration is expected to jump from $15.18 billion in 2026 to $30.27 billion by 2030. This explosive growth is fueled by what customers now expect. After all, 65% of shoppers want personalized recommendations, a feature that simply can't exist without real-time data.
Deciding between batch and streaming often comes down to your specific use case. This table breaks down the key differences to help you choose the right approach for your project.
| Attribute | Batch Ingestion | Streaming Ingestion |
|---|---|---|
| Data Volume | High volume, large chunks | Small, individual events |
| Latency | High (minutes, hours, days) | Low (milliseconds, seconds) |
| Timing | Scheduled intervals | Continuous, 24/7 |
| Cost | Generally lower, more economical | Can be higher due to constant processing |
| Use Case Example | Weekly sales reports, bulk data migration | Real-time stock updates, fraud detection |
| Primary Goal | Processing large datasets efficiently | Reacting to events as they happen |
Ultimately, the choice isn’t about which method is technologically superior, but which one aligns with your business goals. Many sophisticated systems even use a hybrid approach, leveraging batch for large-scale analytics and streaming for immediate operational needs.
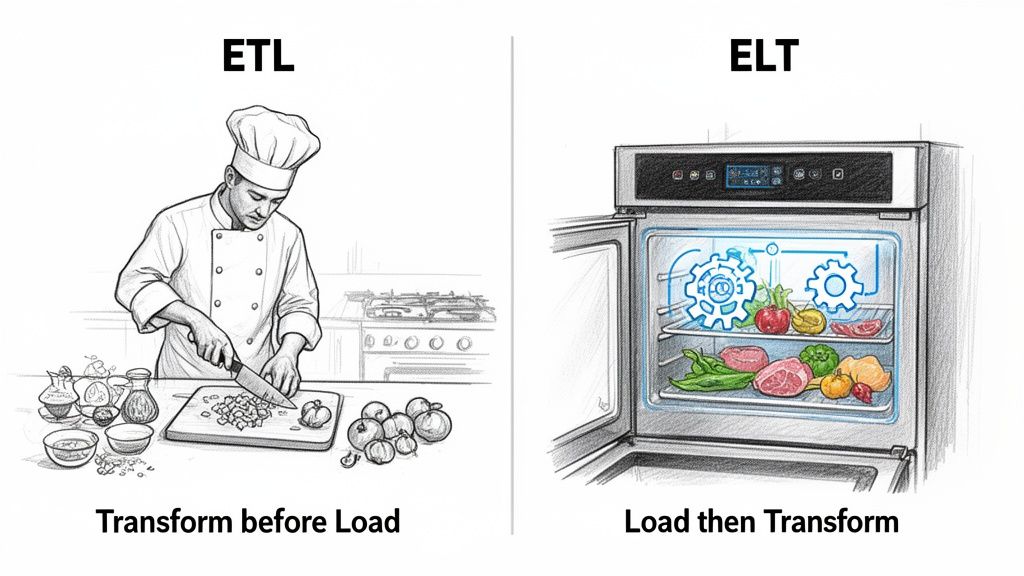
Alright, so we know data can show up in big scheduled drops (batch) or as a constant flow (streaming). But what happens once it arrives? This is where the real work begins.
Two of the most common methods for handling incoming data are ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform). They look almost identical on paper, but swapping that one letter completely changes the game.
To really get it, let's think about it like you're a chef preparing for a dinner service.
With ETL, you’re a traditional chef running a tight kitchen. You do all your prep work upfront, on a separate counter, before anything touches the stove.
First, you Extract your ingredients (the raw data). Then you Transform them by chopping, dicing, and mixing (cleaning, standardizing, and structuring the data). Only once everything is perfectly prepped do you Load it onto the stove to cook (into your final destination system).
In an ETL pipeline, data is cleaned, structured, and validated before it ever gets into your main data warehouse. For years, this was the only way to do it because computer processing and storage were just too expensive to waste on messy data.
This approach gives you incredibly consistent, high-quality data. Everything that enters your core systems is ready to go.
This is a solid, reliable method, especially for compliance and reporting. The downside? It's rigid. If you later realize you needed a piece of raw data you threw away during the "Transform" step, it's gone for good.
Now, imagine a different kitchen. One with a futuristic smart fridge. With ELT, you Extract all your raw ingredients and immediately Load them straight into this powerful appliance.
The transformation happens later. When you're ready to make a meal, you Transform the ingredients right there inside the fridge, which has all the tools you need. You can decide on the fly whether to dice carrots for a soup or blend them for a smoothie.
This is the core idea behind ELT. It takes full advantage of today's cheap cloud storage and massive computing power. You dump all your raw, unfiltered data into a powerful destination like a data lake or a modern data warehouse first. The transformation happens on-demand, right before you run a report or analysis.
This approach gives you incredible flexibility. You never throw away the original raw data, so you can always go back and re-process it in new ways as your business needs change.
For an e-commerce brand, this is huge. A platform like NanoPIM uses a process very similar to ELT with its Data Holding Bay. You can import messy, raw product data from all your suppliers directly into this staging area. Inside the platform, you have the tools to compare, merge, enrich, and validate the information before pushing it live to your storefront.
This ELT-style process gives you total control without ever having to discard potentially valuable data prematurely. You can learn more about how these modern processes come together in our guide to building a data pipeline with ETL and ELT concepts.
Theory is one thing, but seeing data ingestion in practice is where it all clicks. Let’s follow a real-world story to make the data ingestion meaning crystal clear.
Imagine an eCommerce brand, "Urban Threads," getting ready to launch a new line of designer sneakers. Their journey, from a chaotic supplier file to a beautiful Amazon product page, is a perfect, step-by-step example of the data ingestion process.
It all begins with the raw ingredients. Urban Threads gets an email from their supplier with a Dropbox link. Inside is a disaster: a poorly formatted spreadsheet with product names and SKUs, plus a separate folder crammed with hundreds of unorganized, high-res product photos.
First things first, they have to get this jumble of data into their NanoPIM system. The team configures an ingestion workflow that automatically reaches into that Dropbox folder and pulls the spreadsheet and all the images. This is the Extract phase. It's moving the data from its source into a controlled staging environment.
But this new data doesn't just get dumped into their live catalog. That would be asking for trouble.
Instead, it lands in the PIM’s Data Holding Bay. Think of this as a quarantine zone. It’s a temporary space where the new information can be inspected and cleaned before it gets mixed in with the pristine data that powers their store. Automating this transfer effectively often relies on different kinds of data connectors that bridge the gap between systems.
The Holding Bay gives the Urban Threads team a side-by-side view, comparing the new spreadsheet data against their existing product information.
This visual interface immediately flags inconsistencies. Maybe the supplier used "G" for grams, but the company standard is the full word "grams." Now, the team can Transform the data. They map the messy columns to the right attributes, fix formatting errors, and merge the new information without overwriting anything important.
With the data clean and structured, the real work begins. The team uses the PIM's built-in AI tools to enrich the bare-bones specs from the supplier. They generate compelling, SEO-friendly product descriptions, craft bullet points tailored specifically for their Amazon listings, and even create alt-text for all those newly ingested images.
This enrichment step is what turns a data skeleton into content that actually sells.
Here’s a quick look at the final stages of the journey:
What started as a jumbled spreadsheet and a random folder of images has been successfully ingested, transformed, and distributed across all their sales channels. This single, automated workflow saves countless hours, prevents costly data entry errors, and locks in a consistent brand experience everywhere customers shop.
That’s the data ingestion process in action. Turning raw, messy information into a real business asset.
Even the most carefully planned data ingestion strategy is going to hit a few bumps. Let's be honest, no data process is ever perfect, so learning to tackle real-world hurdles is just part of the job. Knowing what to expect is the first step toward building a data pipeline that’s both reliable and smooth.
The most notorious issue, by far, is poor data quality. It's the classic "garbage in, garbage out" problem. If you pull in messy, incomplete, or just plain wrong information from your suppliers, that's exactly what will land in your system. This can potentially cause all sorts of errors on your live storefront.
This isn't just a minor annoyance. Globally, a shocking 85% of big data projects fail because of poor ingestion quality. But on the flip side, successful projects can deliver a 5-10x ROI. It’s a high-stakes game. For many retailers, ingestion bottlenecks are a massive headache, which is why automated tools that can boost data completeness tracking by 40% are so critical. You can dig deeper into how this impacts business outcomes by reading the full data integration market findings.
This flow shows the high-level journey data takes from its source to its final destination in your system.
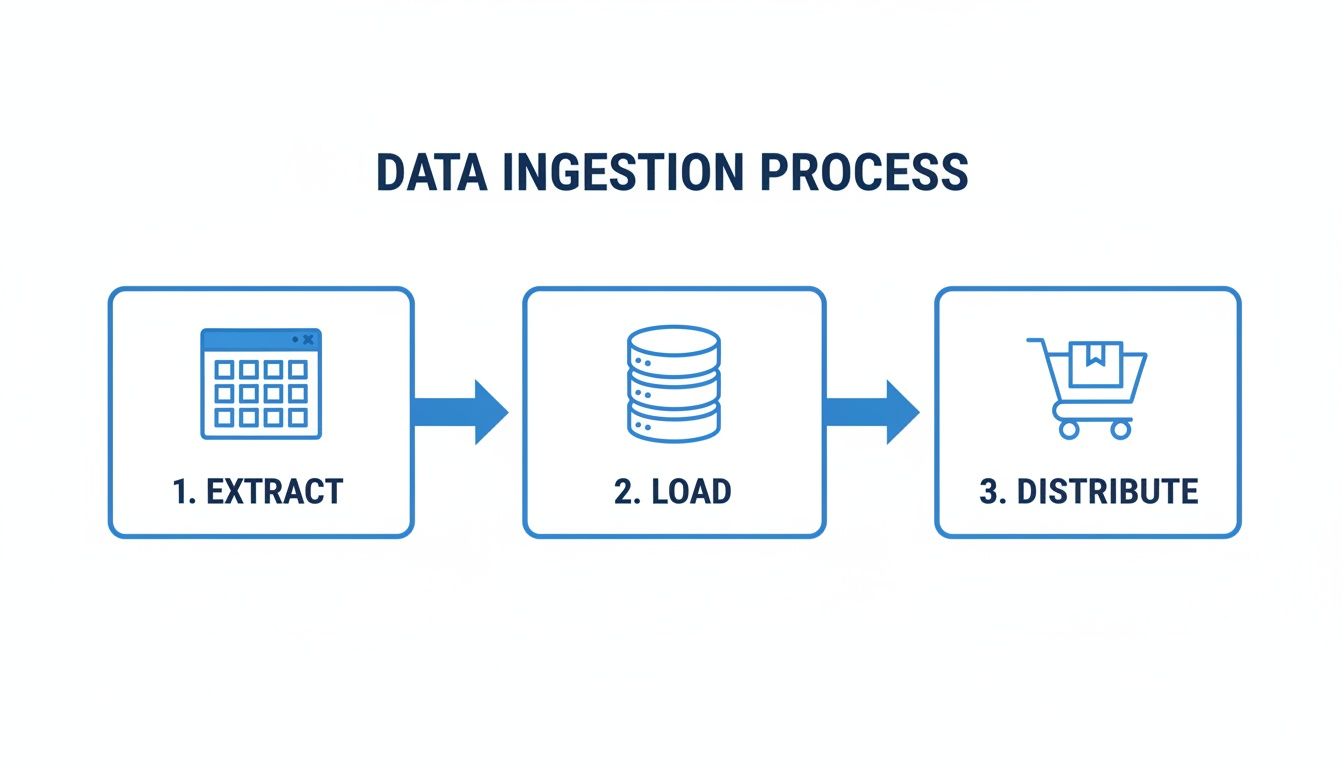
As you can see, data has to be successfully extracted and loaded before it can ever be distributed to a sales channel like your shopping cart.
Another major headache is dealing with a jungle of mismatched data formats. One supplier sends you a CSV file, another an XML file, and a third uses a custom API. Your system needs a way to make sense of all of them without someone having to step in and manually fix things every single time.
This is where a flexible ingestion tool becomes your best friend. The best practice here is to use a system with powerful data mapping capabilities. This lets you create templates that essentially teach the system how to translate each supplier's unique format into your own standardized structure. It automates what would otherwise be an incredibly tedious manual task.
Finally, there’s the constant struggle to keep everything in sync. When inventory levels change or a price gets updated, that information needs to show up everywhere, instantly. Delayed or failed syncs can easily lead to overselling, showing inaccurate prices, and creating a whole lot of frustrated customers.
The solution is a robust ingestion process that can handle real-time updates. By using a PIM with automated validation rules and a staging area like a Data Holding Bay, you can catch errors before they go live and ensure your data is always accurate.
To get a better handle on these issues, you might find our guide on managing data quality for your product catalog useful. By getting ahead of these common problems, you can put the right solutions in place and keep your data pipeline running smoothly.
So far, we’ve dug into the nuts and bolts of what data ingestion means. Now, let's zoom out and talk about the real "why." Getting your data ingestion right isn't just a tech problem to solve. It's your secret weapon.
Think of it as the engine powering your entire eCommerce operation. It’s what lets you spin up AI-driven product descriptions that rank on Google. It’s how you keep your brand’s voice consistent across your website, Amazon, social media, and a dozen other channels. Without a clean, reliable way to get information into your systems, those critical goals are dead on arrival.
The smartest brands know their most valuable asset isn't their warehouse or their ad budget. It's their data. Ingestion is the process that refines that raw, scattered information into something that actually makes you money.
Data ingestion is your secret weapon because it allows you to be agile, consistent, and customer-focused in a crowded digital marketplace. It’s the foundation for turning data into revenue.
This isn't a "set it and forget it" task. A proactive approach to getting data in goes hand-in-hand with how you manage it once it's there. Setting up clear rules from the beginning ensures your data stays clean and trustworthy. You can see how this works by exploring these data governance policies and how they create a healthy data ecosystem.
When you nail data ingestion, you get the power to turn messy spreadsheets, supplier feeds, and random updates into a loyal customer base and a healthier bottom line. It's the first, and most important, step to winning with data.
Even after a deep dive into data ingestion, it's natural to have a few questions floating around. Let's clear up some of the most common ones you might have about what data ingestion really means and how it works in the real world.
Think of data ingestion as the big-picture goal: getting data from anywhere into a system where you can actually work with it. ETL (Extract, Transform, Load) is just one specific recipe for how to pull that off.
In a classic ETL process, you extract the data, clean it up and reshape it (the "transform" step), and then you load that polished, finished data into its final destination.
But data ingestion is a broader category that also includes other methods, like ELT (Extract, Load, Transform), where you dump the raw data in first and worry about cleaning it up later. Ingestion is the "what," and ETL is just one popular way of doing the "how."
Data ingestion isn't just helpful for Product Information Management (PIM). It's the absolute bedrock of any good PIM system. A PIM’s whole purpose is to be the single source of truth for product data that's usually scattered across supplier spreadsheets, ERPs, and messy folders of images.
Data ingestion is the engine that automatically pulls all that disconnected, messy information into the PIM. Without a solid ingestion pipeline, you're stuck with manual uploads, a soul-crushing process that’s a guaranteed recipe for errors and delays.
A well-designed ingestion process automates all of this. It ensures your PIM is constantly fed with the most current, accurate data available, which means your product content is always reliable and ready for every sales channel.
Absolutely. It wasn't that long ago that data ingestion was a complicated, expensive beast only large corporations with massive IT budgets could afford to tame. Modern, cloud-based tools have completely changed the game.
Today, powerful data automation is within reach for businesses of any size.
Many platforms, especially modern PIMs, come with user-friendly, built-in ingestion features that you can set up without a team of developers. Better yet, many of these tools run on flexible, pay-as-you-go pricing models.
This means a small business can automate its data workflows, save a staggering amount of time, and compete on a much more level playing field. You only pay for what you use, making it an incredibly cost-effective way to manage your data like a much bigger enterprise.
Ready to stop wrestling with messy spreadsheets and start winning with data? NanoPIM centralizes all your product information and uses AI to create perfect, channel-ready content, all powered by a simple yet robust data ingestion engine. See how it works.


