
Let's get straight to it. People often get tangled up in the data vs metadata debate, but the difference is actually quite simple. Data is the raw fact. Metadata is the story about that fact.
For instance, your product's name, 'Trailblazer Hiking Boots', is data. The SKU it's assigned, the date it was added to your system, and the file type of its main image, that’s all metadata.
Think of it like a recipe. The ingredients, flour, sugar, eggs, are your data. The recipe card that tells you what each ingredient is, how much to use, and the baking instructions? That's your metadata. Without that card, you just have a pile of ingredients with no purpose.
To really grasp the difference between data and metadata, you have to look past the textbook definitions and see how they actually work in an eCommerce business. Data represents the raw facts and figures you collect every day. Things like sales numbers, customer clicks, or inventory levels. It tells you what happened, but that's about it.
Metadata, on the other hand, gives you the all-important context. It’s the "data about the data." It explains where the information came from, who created it, and when it was last updated. This layer of information is what makes your raw data structured, searchable, and ultimately, trustworthy.
This infographic breaks it down perfectly, using that same recipe analogy.

As you can see, the data is the core content. But without the organization and meaning that metadata provides, that content isn't very useful.
The easiest way to tell data and metadata apart is to look at their jobs. When you know what each one is supposed to do, managing your product information becomes a whole lot easier.
For example, your analytics dashboards pull in data to show you how the business is performing. Your internal systems, like a PIM or DAM, rely on metadata to make all that information findable, consistent, and compliant with your rules.
The question I always tell my team to ask is: "Does this information describe something, or is it the thing itself?" A price of $149.99 is the thing (data). The currency 'USD' is the description (metadata).
This table gives you a quick, at-a-glance comparison to nail down the core differences, with a few common eCommerce examples thrown in.
| Aspect | Data (The 'What') | Metadata (The 'About the What') |
|---|---|---|
| Purpose | To be analyzed for insights and used in operations. | To add meaning, structure, and context to data. |
| Example | The text 'Water-Resistant Hiking Boots'. | The field label 'Product Name' and its character limit. |
| Change Rate | Changes constantly with sales, inventory, and updates. | Changes less often, usually when business rules are redefined. |
| Business Value | Drives immediate outcomes like sales or inventory alerts. | Builds long-term trust, compliance, and searchability. |
Ultimately, data gives you the power to act now, while metadata builds the foundation that makes your data reliable and valuable over the long haul. You absolutely need both to run a modern eCommerce operation effectively.
Okay, we’ve laid the groundwork. Now let’s talk about how the data vs. metadata distinction actually plays out in your day-to-day work. The most important difference comes down to how they change over time.
Data is dynamic. It’s the living, breathing pulse of your business, constantly shifting with every sale, inventory adjustment, or customer click.
Metadata, on the other hand, is structural and far more stable. It’s the framework. You only change it when your business rules evolve, like adding a new product line, updating a compliance standard, or creating a new attribute like a ‘sustainability score.’ It gives your ever-changing data a place to live.

Getting this right is the key to building systems that can scale. When you treat them the same, you’re inviting costly chaos into your operations. But when you manage data and metadata according to their unique roles, everything just runs better.
Think about it in the context of a retail business selling outdoor gear.
This split defines who does what. Your sales and inventory teams are on the front lines, constantly interacting with and creating new data. Meanwhile, your data governance or product information teams act as the guardians of the metadata, making sure the entire system stays organized and logical.
In a typical retail setting, data changes with every single transaction, while the metadata that defines 'transaction' might only be updated once a year. This stability is what allows for reliable reporting and analytics over time.
Because data is so fluid, it requires systems built for high-volume, rapid-fire updates. Metadata needs something different, a system focused on governance, versioning, and maintaining structural integrity. Mistaking one for the other is a direct path to operational friction and bad business intelligence.
While metadata changes far less often than data, its role in governance creates massive business value. Raw data is a firehose; global eCommerce data volumes are projected to hit 2.5 quintillion bytes daily by 2026. The metadata that defines that data, however, like ownership, formats, and sources, only shifts when the business itself shifts.
This context is what separates noise from insight. For example, simple metadata like 'sales rep ID' or 'last modified: 2026-03-15' can fuel AI-driven sales forecasts with up to 25% higher accuracy. It's why Gartner forecasts that 70% of enterprises will get serious about metadata management by 2026, scrambling to avoid the estimated $12.9 trillion in costs that stem from poor data quality.
If you want to go deeper, you can see more stats and explore the powerful role of metadata in business analytics.
In the world of eCommerce, everyone talks about data. Sales data, customer data, traffic data, it gets all the attention. But behind every great online store, it’s the metadata that’s quietly doing the heavy lifting.
Metadata is the difference between a frustrating, cluttered digital storefront and a seamless, intuitive shopping experience. It’s the invisible engine that turns raw information into real revenue.
Think about your last online purchase. Did you filter by size, color, or brand? Those filters didn’t work by magic. They worked because of metadata tags like color: navy blue or water-resistant: yes that give meaning to each product. This is where the whole "data vs. metadata" debate stops being a technical squabble and becomes a critical business conversation.
Properly managed metadata is the bedrock for everything from helping a customer find the perfect item to helping your own teams manage inventory. It’s what powers search, personalization, and countless operational workflows. Without it, your product catalog is just a digital pile of disconnected things.
When someone lands on your site and types into the search bar, they expect instant, accurate results. That relevance is a direct product of good metadata. If a shopper searches for "noise-cancelling wireless earbuds," your site's search engine shouldn't just be scanning for those words in the product title.
Instead, it should be scanning metadata fields to pinpoint products with specific attributes:
This kind of detail ensures the customer sees exactly what they asked for, which dramatically improves their on-site experience. The same logic powers faceted search, those filters on the side of a category page. Each filter is a metadata attribute that empowers shoppers to drill down from thousands of products to the one that’s just right for them.
This isn't just a nice feature to have; it directly drives sales. Weak metadata leads to weak search results, and customers who can't find what they're looking for will simply go somewhere else.
Think of it this way: Your data is the product sitting on the shelf. Your metadata is the entire system of aisles, signs, and labels that guides a customer straight to it. Without that system, your store is a chaotic mess.
Getting this wrong has a serious financial cost. A recent Gartner study noted that poor metadata management can slash search relevance in product catalogs by 30-40%, hitting revenue directly. On the flip side, when metadata correctly tags a product, it can boost conversion rates by up to 25%. With IDC predicting that 75% of all enterprise data will be unstructured by this year (2026), the potential for lost opportunity is massive.
Good metadata doesn't just benefit the customer; it brings a huge amount of order to your internal operations. Imagine your marketing team trying to find all product photos from the "fall collection" that are approved for social media use.
Without metadata, that’s a painful, manual job of sifting through folders and praying the filenames make sense. With metadata, it’s a quick search.
This is precisely where a Digital Asset Management (DAM) system becomes so powerful. A DAM uses metadata to make every single file, from product shots and videos to technical spec sheets, instantly discoverable, trackable, and compliant. You can learn more about the benefits of Digital Asset Management in our detailed guide.
This organizational strength touches every part of the business:
By creating a single source of truth governed by clear metadata, you break down information silos, cut down on manual errors, and let your teams focus on growing the business instead of just cleaning up messes. In the data vs. metadata discussion, it’s metadata that ensures your data is consistent, reliable, and ready to go to work.

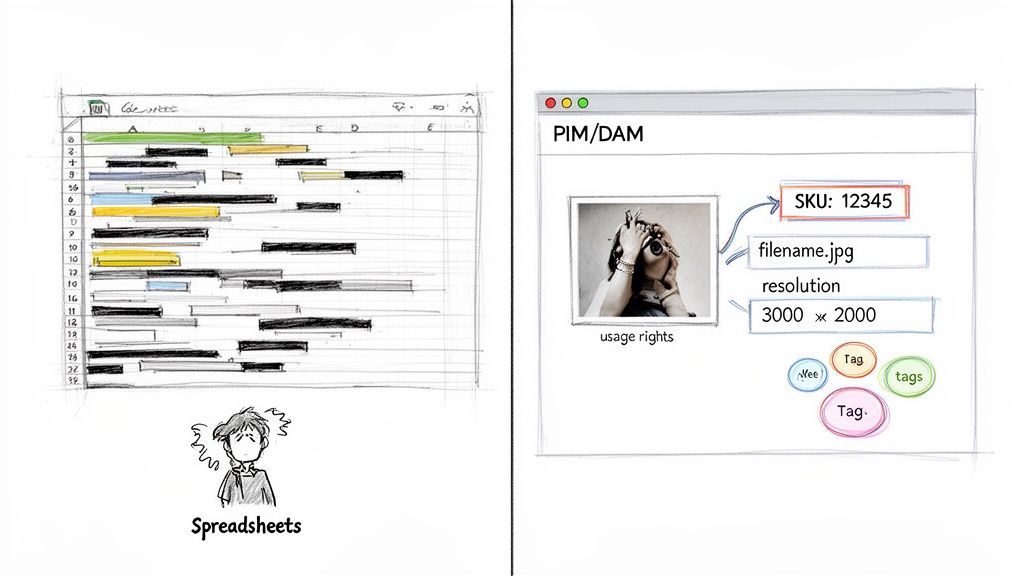
Alright, let's stop talking theory. The real magic happens when you see how data and metadata actually function inside the tools you use every day, like a Product Information Management (PIM) or Digital Asset Management (DAM) system. This is where the two work in tandem to bring order to the chaos of modern commerce.
In these systems, your product content is the data. The metadata is the invisible framework that organizes, connects, and ultimately gives that data its meaning. Grasping this relationship is the key to understanding why these platforms are indispensable.
Picture this: you've just received a new lifestyle photo of a winter coat for an upcoming campaign. The image file itself, the actual pixels making up the picture, is the data.
But on its own, that file is just a dead-end digital object floating on a server. It's the metadata that transforms it into a valuable, searchable business asset.
Here's what that looks like in a modern DAM:
Winter_Coat_FW26_Lifestyle_01.jpg (Descriptive metadata)3000x4500px (Technical metadata)Approved for Social Media until 2026-12-31 (Administrative metadata)winter coat, outerwear, womens fashion (Descriptive metadata)SKU-WC-NAVY-M (Structural metadata, tying the image to a specific product)Without this context, your team would burn hours trying to find the right image, let alone figuring out if they're even allowed to use it. With proper metadata, the asset becomes instantly findable, compliant, and ready to deploy.
Now, let's shift over to the product information itself within a PIM. The raw specifications for that same winter coat are the data. A single piece of data might be the text '800-fill down'.
A great fact, but it’s pretty useless without context. A PIM like NanoPIM builds a rich, structured product story around that single data point using metadata. If this is new territory for you, we have a great guide explaining what a PIM system is and how it all works.
The metadata provides the essential structure:
Insulation Type (This field houses the data '800-fill down')Outerwear > Coats & Jackets (This is how the product is classified)Medium size is linked to Small and Large versions under a single parent product.This structured approach lets you manage entire product families with ease. A single update to the parent product's description automatically cascades down to all its variants, no more soul-crushing copy-pasting.
In the PIM vs. DAM world, think of it like this: The PIM manages the metadata that defines the product, while the DAM manages the metadata that describes the visuals that represent it.
To really see the power here, just compare a business stuck managing its catalog in spreadsheets to one that's upgraded to a PIM.
Before (Spreadsheet Hell):
The marketing team is staring at a spreadsheet with thousands of rows. The 'Insulation' column is a complete mess with inconsistent entries: '800-fill', 'down 800', and '800 fill power down'. Trying to find all down-filled jackets is a nightmare of endless filtering and manual cleanup. Meanwhile, product images are buried in a shared drive with cryptic names, leading to the wrong photo being used on a major marketplace listing. Sound familiar?
After (An AI-Powered PIM):
The product manager imports that same messy spreadsheet. The PIM enforces consistency with a dedicated attribute, Insulation Type, which uses a clean dropdown list. An AI assistant helps map and normalize the old, messy data into the new, structured format. Better yet, the PIM is connected to the DAM, so each product SKU is directly linked to its approved, metadata-rich images.
Now, launching that winter coat on a new retail channel is a one-click action that pulls all the correct, consistent information and assets automatically. This organized system reduces errors by over 90% for many teams and slashes time-to-market from weeks to days.
Ignoring the nuances of the data vs. metadata discussion isn't just a technical oversight. It’s a genuine business risk with very real consequences. When the context surrounding your data is weak, inconsistent, or just plain missing, problems begin to snowball. It's a chain reaction that impacts everything from customer trust to your team's sanity.
The most immediate fallout? Inconsistent product information. One channel lists a shirt as ‘Navy Blue,’ while another calls it ‘Midnight.’ A customer spots two different prices on two different marketplaces. This isn't just unprofessional; it actively confuses shoppers, erodes trust, and sends them straight to a competitor. Those are sales you'll never get back.
Beyond the obvious revenue hit, there’s the silent killer of productivity: inefficient workflows. Think of all the hours your teams waste hunting for the right digital asset or cross-referencing spreadsheets to fix conflicting product specs. It’s more than just frustrating, it’s a massive resource drain that pulls your best people away from innovation and traps them in a cycle of digital janitorial work.
The good news is that these problems are entirely avoidable. The fix lies in moving away from scattered, manual processes and embracing a centralized system with clear rules of engagement. This is where a modern PIM platform, especially one with integrated DAM capabilities, becomes your command center for both data and metadata.
This approach gives you two critical layers of defense. First, a centralized repository creates a single source of truth for every product and asset, period. Second, a human-in-the-loop review process ensures that any changes are validated before they go live and cause chaos.
This simple but powerful framework helps you stop playing defense and start building a product information ecosystem you can actually rely on. To see just how effective this is, let's look at the most common risks businesses face and how a PIM directly neutralizes them.
| Common Risk | Business Impact | How a PIM Platform Solves It |
|---|---|---|
| Inconsistent Product Info | Confused customers, lost sales, and brand erosion. | Creates a single source of truth where all product data and metadata live, ensuring consistency across every channel. |
| Inefficient Workflows | Wasted hours on manual data entry and asset searches. | Automates the distribution of information and uses rich metadata to make any asset instantly findable. |
| Compliance and Legal Issues | Using expired images or incorrect product claims. | Tracks usage rights, approval statuses, and version history for every asset and data point, creating a clear audit trail. |
| Poor Customer Experience | Inaccurate search results and broken product filters. | Enforces a strict metadata structure, which directly powers a clean, accurate, and intuitive on-site search experience. |
Ultimately, a PIM/DAM system transforms these pain points into strategic advantages, giving you back control over your brand and operations.
History shows us time and again that metadata often holds more long-term value than the raw data it describes. Just look at the Library of Congress's Chronicling America project. While the old newspaper articles are fascinating data, it's the rich metadata, dates, locations, topics, that makes them discoverable. Research shows that incomplete metadata can hide up to 40% of sources from users.
Fast forward to today, a 2026 Deloitte study found that a staggering 82% of retailers struggle with disconnected metadata. This contributes to an estimated $2.5 trillion in annual losses from inconsistent product info alone. You can discover more insights about data challenges and best practices to see just how deep this problem runs.
Protecting your business from these risks isn't about micromanaging every single data point. It’s about building a strong metadata governance strategy that makes your data trustworthy, traceable, and ready for any channel, at any time.
By implementing a centralized system like a PIM, you build a fortress around your most valuable digital assets. You ensure every piece of data is enriched with the right metadata, reviewed by the right people, and delivered to your customers with absolute confidence.
That’s not just good data management. It’s a powerful competitive advantage.
Ready to put a real system in place? This is your playbook for building a metadata strategy that doesn't just fix today's headaches but sets you up for what's coming next, like advanced AI search. It’s all about creating a scalable, reliable foundation for your product information.
A huge piece of this puzzle is a solid Data Strategy And Governance framework. You simply can't have a future-proof metadata plan without knowing how to govern your data assets. This framework sets the rules of the road for everything that follows.
First things first: you need to decide what information you actually need to track. Don't just copy another company’s setup. Step back and think about what your customers genuinely need to make a buying decision, and what your internal teams need to keep the wheels turning.
Start by asking a few pointed questions:
Going through this exercise helps you build a metadata model that’s tailored to your business, not just a bloated list of fields you'll never use. Keep it lean at first and focus on what delivers immediate, tangible value.
Once you know what to track, you need to set the rules for managing it. This is where governance comes in. Without it, even the most perfect metadata model will descend into chaos surprisingly fast.
A metadata strategy without governance is like a library with no librarian. The books might be there, but no one can find what they need, and there's no system to keep things from turning into a mess.
Your governance plan should be straightforward. It needs to clearly define who is responsible for creating, updating, and approving product information. A platform like NanoPIM helps by letting you set up human-in-the-loop review workflows, making sure every change is double-checked before it goes live. For a much deeper dive, check out our guide on creating a data governance strategy that actually works.
You don't have to overhaul everything at once. A great way to get started is by figuring out where you are right now and identifying a few quick wins. This approach builds momentum and shows your team the immediate value of having a structured system.
Use this simple checklist to find your best starting point:
By focusing on these practical steps, you start turning your product information from a messy liability into a powerful asset. This isn’t just about cleaning up data; it’s about building a system that drives real growth and gets you ready for the future of commerce.
Even with clear definitions, the line between data and metadata can get fuzzy in the real world. That’s normal.
Here are a few of the most common questions we get from eCommerce teams wrestling with their product information.
Yes, absolutely. This is probably the biggest source of confusion, and the answer always comes down to context.
Think about a product’s price. That $49.99 is pure data. But what if you run a report on the average price of all hiking boots you sold last quarter? Suddenly, that average price becomes metadata that describes the performance of an entire product category.
It’s all about your point of view.
Tags are a simple form of metadata, and they’re useful for adding flexible, searchable terms to assets. You might tag a lifestyle shot with fall collection or outdoors. So far, so good.
The problem is that tags have no structure. A solid metadata strategy relies on specific, defined fields like Color, Material, or SKU. This structure is non-negotiable if you want reliable filtering, accurate syndication to channels like Amazon or Google Shopping, and automation that doesn’t break.
Relying only on tags is a shortcut to chaos and inconsistency.
This is a classic trick question. The real answer is that you can't have one without the other. Data is the content, but metadata gives it meaning.
An image file (data) without its usage rights, expiration date, and associated product link (metadata) is just a ticking time bomb, an orphaned asset waiting to cause problems.
Think of it like this: Data is the "what," and metadata is the "so what?" Data tells you a shirt is blue. Metadata tells you that "blue" is a filterable attribute that helps customers find and buy that shirt.
To keep your system clean and effective, you’ll constantly need to manage and sometimes change document metadata to reflect new rules or fix errors. The goal isn’t to pick a favorite, but to create a system where data and metadata work together perfectly.
Ready to stop fighting with spreadsheets and build a single source of truth for your products? See how NanoPIM centralizes your data and metadata to drive consistency and growth. Explore the platform at https://nanopim.com.


